Amar GajbhiyeinLevel Up CodingEasy Guide to Create a Write Data Source in Apache Spark 3Step by step guide for creating a transactional write data source in Apache Spark 3.0.xNov 2, 20203Nov 2, 20203
Amar GajbhiyeinLevel Up CodingEasy Guide to Create a Custom Read Data Source in Apache Spark 3Step by step guide for writing a custom read data source in Apache Spark 3.0.x with location-aware and multi-partition supportOct 19, 20201Oct 19, 20201
Amar GajbhiyeDomain-Driven Approach Towards Software DesignA practical design guide for the complex systemsMay 10, 2020May 10, 2020
Amar GajbhiyeHow to Make Apache Ignite Production ReadyActionable guidelines to make Apache Ignite production-ready.Feb 14, 2020Feb 14, 2020
Amar GajbhiyeLombok: Remove boilerplate code from Java source filesProject Lombok is the boilerplate code generator library for Java. It autogenerates Java bytecode in .class files for different…Feb 10, 2020Feb 10, 2020
Amar GajbhiyeHow to Secure Apache Ignite cluster?System security is a very important aspect of any data system. In this article, we will discuss how to secure Apache Ignite cluster.Sep 14, 20191Sep 14, 20191
Amar GajbhiyeHow to handle Network Segmentation in Apache Ignite?Apache Ignite like any other distributed system, needs to handle network partitioning. It can be done by writing Network segmentation…Sep 14, 2019Sep 14, 2019
Amar GajbhiyeApache Spark: Custom streaming data sourceA custom streaming data source helps us integrate our stream source with Apache Spark and lets us leverage its stream processing.Aug 19, 2019Aug 19, 2019
Amar GajbhiyeApache Spark Custom Data SourceLearn how to create custom Apache Spark data sourceJul 29, 2019Jul 29, 2019
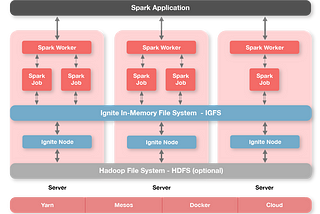
Amar GajbhiyeApache Spark and in-memory Hadoop File System (IGFS)Apache Spark and in-memory Hadoop File System (IGFS)Jul 5, 2019Jul 5, 2019